In this new post series on data science productivity through choice of tools: BigQuery is under the limelight as a transformative tool for an early-stage startups! In my first post I make a case for adopting BigQuery and advocate its widespread use across the organization, as an essential building-block towards a data intelligent culture.
As my own interests and responsibilities have started to align more towards institutionalizing data practices and infrastructure at lean, growth-mode organizations; I’ve been exploring better engineering tools and platforms for data science productivity. Growth focus, especially for maturing data teams, can sometimes be be a cacophonous experience - cloud platforms, analytics vendors, infrastructure, testing frameworks or science deployments all being worthwhile targets. With expectation management as a preliminary to data success: the first investment in technical real-estate for small data shops must always be analytics and decision-support.
Towards this goal, data engineering is almost always the first bottleneck one should consider prioritizing. The right choice of analytics vendor and engineering infrastructure, can go a long way towards alleviating grave concerns and issues further down the growth cycle. There are tonnes of options out there, from choice of analytics providers to date-warehousing stores to ETL pipelines that move all your data! A good number of factors set the Google Cloud Platform apart from market competition. For our team: its pervasive utility, expansive suite of ancillary tools and ready integrations with a host of popular existing DS tools and technologies lead to enthusiastic adoption. In this post, adhering to the philosophy of minimizing technical debt - I make a case for Google BigQuery as the sustainable tool of choice for a rapidly-growing data shop.
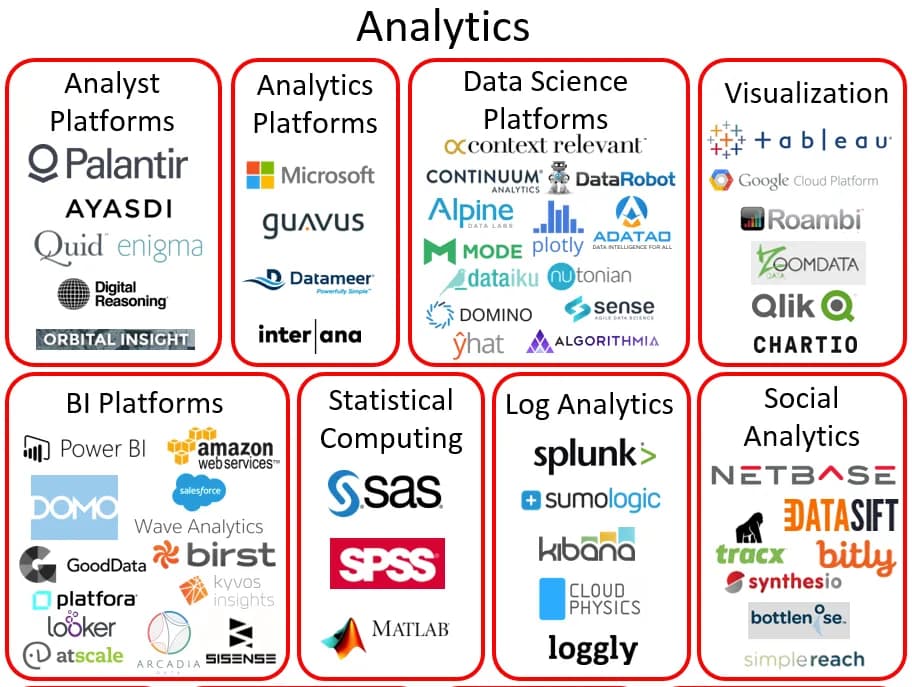
©️ Matt Turck (@mattturck), Demi Obayami (@demi_obayami), & FirstMark(@firstmarkcap)
Figure | Current landscape of analytics vendors
Small Shop, Big Data
Representative of majority; our use-case too begins with the story of a young organization learning to harness available data. At tech-enabled startups, company composition is usually a significantly large fraction of engineers, followed by product owners and analysts, with varying degrees of analytical abilities (I’m going to stack leadership in with this group), and finally an exclusive group of quants that straddle the line between advanced experimental modeling and engineering.
It follows logically that any tool, platform or infrastructure that is institutionalized, should be representative of the organizational structure and its core users. This is difficult in practice, since data scientists prefer consuming technologies that have too high a learning curve for organization-wide appeal. Ergo, our data analytics solution needs to have “universal appeal”.
A good rule of thumb is a SQL flavored solution - which balances simplicity (syntax and structure) and functionality. Eventually, I was able to conclude that BigQuery is an ideal solution motivated by three takeaways:
- Easy setup
- Easy learning curve, even for advanced features
- Easy computation
In a nutshell my observation was that with some engineering support; it’s extremely simple to have the Google Cloud Platform(GCP) integrated within your organization. With a host of helpful documentation, users across our organization were able to onboard with surprising ease. Finally, and this is what’s most likely to convince scientists, analysts and engineers; if you so desire BigQuery abstracts all of its many application and data storage layers to allow you to interface with the entire Infrastructure as a Service (IaaS) product - simply through SQL!
A League of Their Own
I’m going to take a deeper dive in to BigQuery as a product offering. Perhaps, the most sensible approach would be to first draw comparisons between BigQuery and its closest peers/competitors. As an IaaS provider with cloud storage, BigQuery has a lone competitor AWS, with its Athena and Redshift offerings. In most scenarios, the flavor of your organizational marriage (with either AWS or GCP) is the deciding factor and not really a competitive analysis of the two providers.
With that being said, as I mentioned earlier, BigQuery is a unique product. It offers no constraints on storage capacity or compute resources unlike Redshift. BigQuery leverages a distributed underlying data store to split queries into sub-queries. These sub-queries are then executed in parallel and reassembled. While Athena does offer a serverless alternative to Redshift, the similarities end there. BigQuery manages data formats internally (hence optimizing it for querying) and also queries data outside of its storage system.
Organizational benefits of BigQuery
- Fully-managed storage and optimization
- Elastic, serverless, cloud-native SQL analytics
- Support for unstructured data formats
- 1TB worth of free query computation per month
- Packaged with GCP which offers a host of other cloud services - Analytics 360, Data Studio, Sheets et al., catering to data/analysis needs of the entire organization.
Outro
Data only leads to insight post-analysis; in order to leverage data for strategic decision-making - planning data analytics initiatives is paramount to growth. With a large options pool of tools, vendors and software; we settle on very simple guidelines to winnow away inferior players and pave a path towards analytical success. I can personally recommend the Google Cloud analytics offering - BigQuery on the basis of its feature completeness, performance capabilities, SQL support and lastly an extremely business user-friendly self-service solution model.